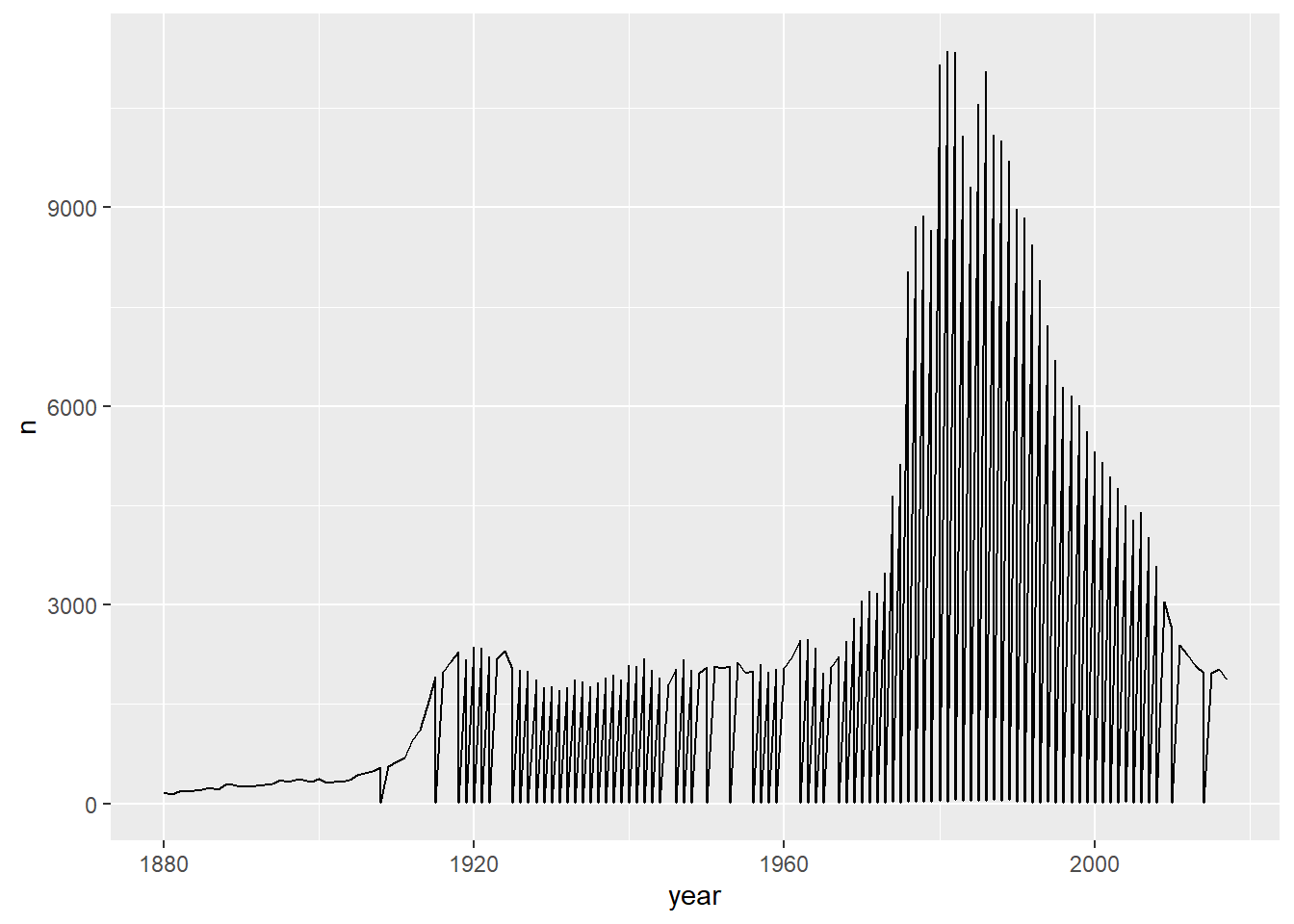
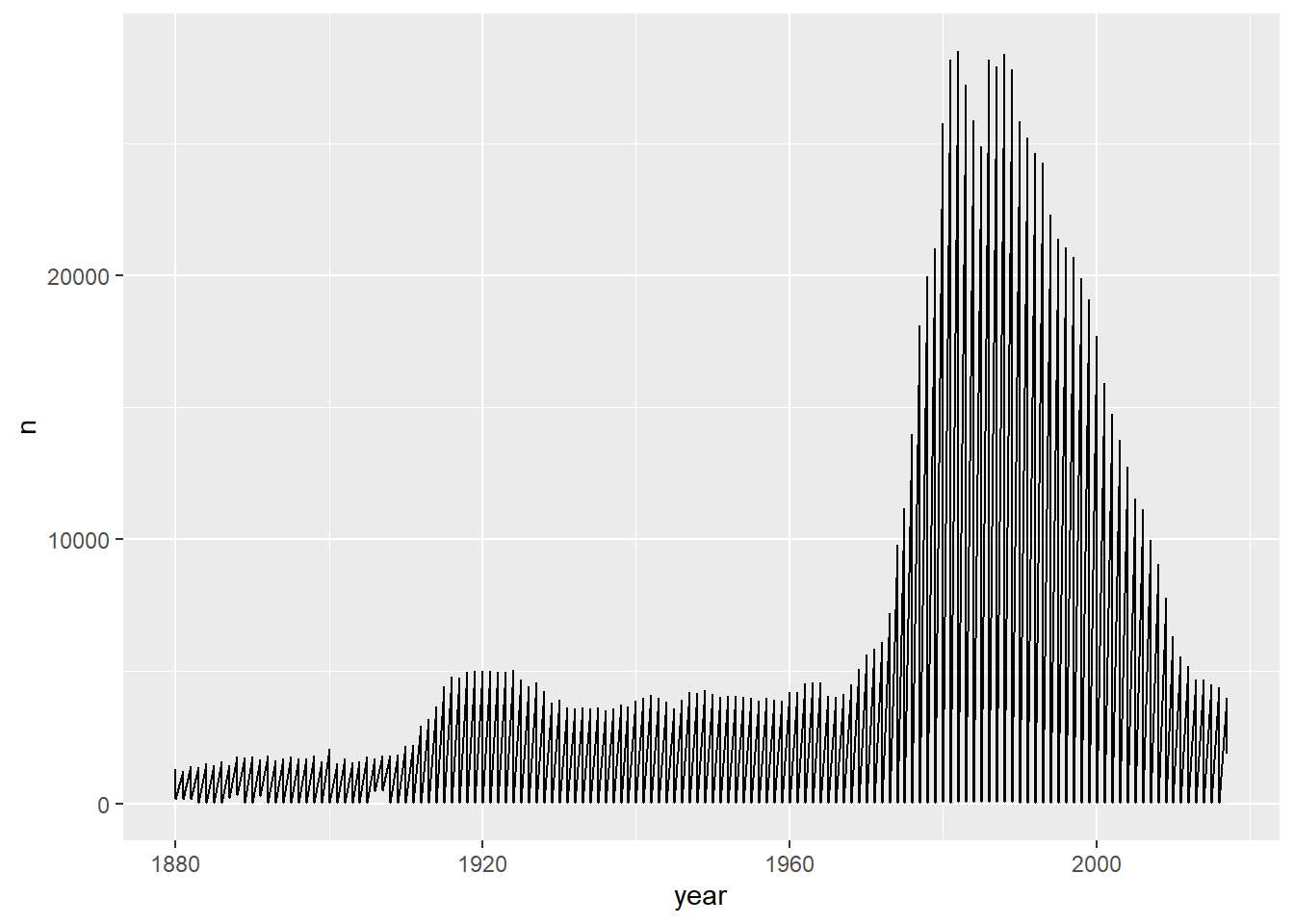
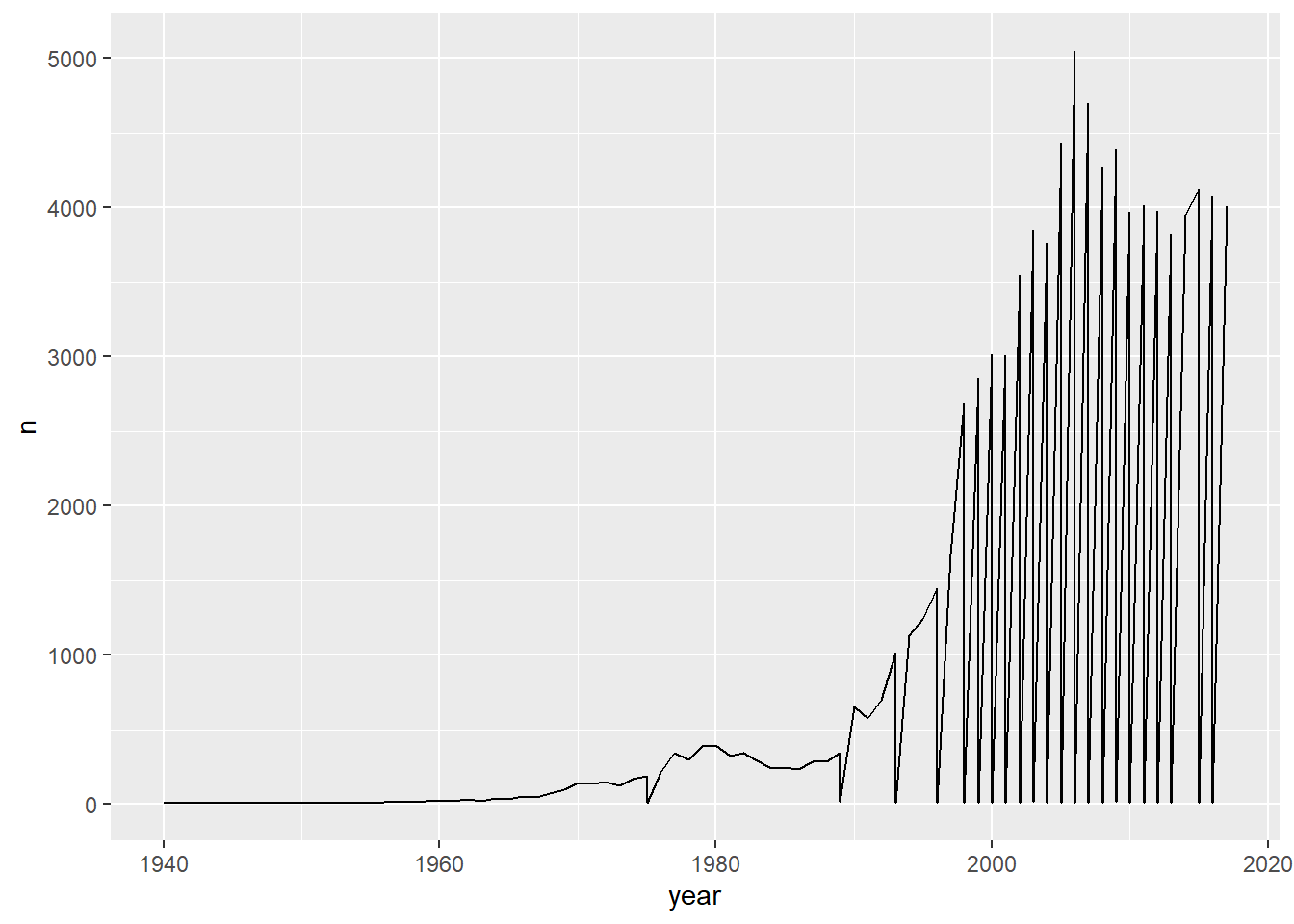
I am writing this for Arvind’s class. Its kind of interesting.
My First Piece of R Code
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(ggformula)
Loading required package: scales
Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
Loading required package: ggridges
New to ggformula? Try the tutorials:
learnr::run_tutorial("introduction", package = "ggformula")
learnr::run_tutorial("refining", package = "ggformula")
library(babynames)
Using the babynames library to get a list of data
babynames
# A tibble: 1,924,665 × 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.0724
2 1880 F Anna 2604 0.0267
3 1880 F Emma 2003 0.0205
4 1880 F Elizabeth 1939 0.0199
5 1880 F Minnie 1746 0.0179
6 1880 F Margaret 1578 0.0162
7 1880 F Ida 1472 0.0151
8 1880 F Alice 1414 0.0145
9 1880 F Bertha 1320 0.0135
10 1880 F Sarah 1288 0.0132
# ℹ 1,924,655 more rows
Filtering the data
babynames %>%filter (name =="Sara")
# A tibble: 222 × 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Sara 165 0.00169
2 1881 F Sara 147 0.00149
3 1882 F Sara 180 0.00156
4 1883 F Sara 183 0.00152
5 1884 F Sara 197 0.00143
6 1885 F Sara 215 0.00151
7 1886 F Sara 247 0.00161
8 1887 F Sara 214 0.00138
9 1888 F Sara 293 0.00155
10 1889 F Sara 286 0.00151
# ℹ 212 more rows