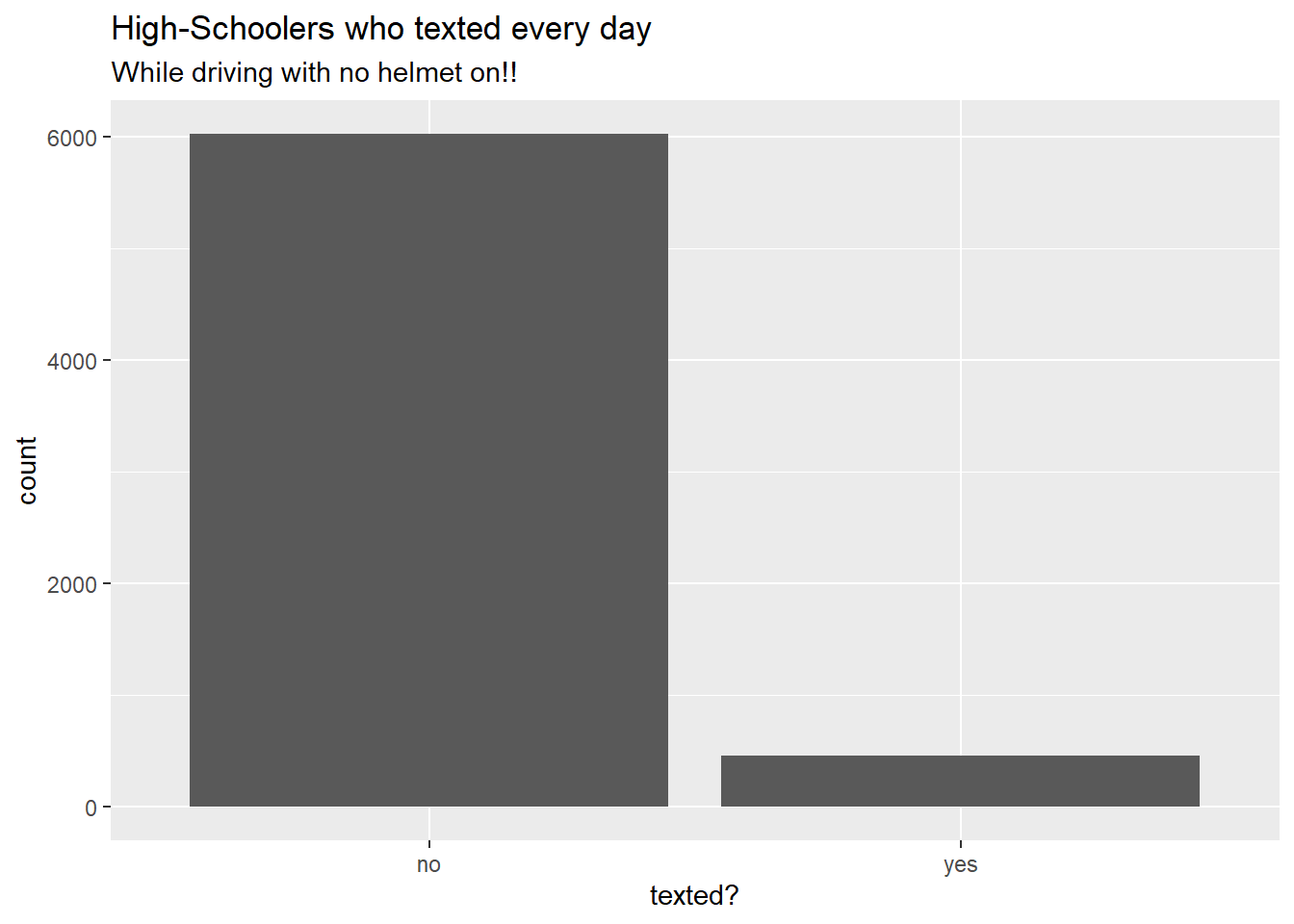── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(mosaic)
Registered S3 method overwritten by 'mosaic':
method from
fortify.SpatialPolygonsDataFrame ggplot2
The 'mosaic' package masks several functions from core packages in order to add
additional features. The original behavior of these functions should not be affected by this.
Attaching package: 'mosaic'
The following object is masked from 'package:Matrix':
mean
The following objects are masked from 'package:dplyr':
count, do, tally
The following object is masked from 'package:purrr':
cross
The following object is masked from 'package:ggplot2':
stat
The following objects are masked from 'package:stats':
binom.test, cor, cor.test, cov, fivenum, IQR, median, prop.test,
quantile, sd, t.test, var
The following objects are masked from 'package:base':
max, mean, min, prod, range, sample, sum
library(ggformula)library(infer)
Attaching package: 'infer'
The following objects are masked from 'package:mosaic':
prop_test, t_test
library(resampledata)
Attaching package: 'resampledata'
The following object is masked from 'package:datasets':
Titanic
library(openintro)
Loading required package: airports
Loading required package: cherryblossom
Loading required package: usdata
Attaching package: 'openintro'
The following object is masked from 'package:mosaic':
dotPlot
The following objects are masked from 'package:lattice':
ethanol, lsegments
data(yrbss, package ="openintro")yrbss
# A tibble: 13,583 × 13
age gender grade hispanic race height weight helmet_12m
<int> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
1 14 female 9 not Black or African Americ… NA NA never
2 14 female 9 not Black or African Americ… NA NA never
3 15 female 9 hispanic Native Hawaiian or Othe… 1.73 84.4 never
4 15 female 9 not Black or African Americ… 1.6 55.8 never
5 15 female 9 not Black or African Americ… 1.5 46.7 did not r…
6 15 female 9 not Black or African Americ… 1.57 67.1 did not r…
7 15 female 9 not Black or African Americ… 1.65 132. did not r…
8 14 male 9 not Black or African Americ… 1.88 71.2 never
9 15 male 9 not Black or African Americ… 1.75 63.5 never
10 15 male 10 not Black or African Americ… 1.37 97.1 did not r…
# ℹ 13,573 more rows
# ℹ 5 more variables: text_while_driving_30d <chr>, physically_active_7d <int>,
# hours_tv_per_school_day <chr>, strength_training_7d <int>,
# school_night_hours_sleep <chr>
yrbss %>%group_by(helmet_12m) %>%count()
# A tibble: 7 × 2
# Groups: helmet_12m [7]
helmet_12m n
<chr> <int>
1 always 399
2 did not ride 4549
3 most of time 293
4 never 6977
5 rarely 713
6 sometimes 341
7 <NA> 311
no_helmet_text <- yrbss %>%filter(helmet_12m =="never") %>%mutate(text_ind =ifelse(text_while_driving_30d =="30", "yes", "no")) %>%# removing most of the other variablesselect(age, gender, text_ind)no_helmet_text
# A tibble: 6,977 × 3
age gender text_ind
<int> <chr> <chr>
1 14 female no
2 14 female <NA>
3 15 female yes
4 15 female no
5 14 male <NA>
6 15 male <NA>
7 16 male no
8 14 male no
9 15 male no
10 16 male no
# ℹ 6,967 more rows
no_helmet_text %>%drop_na() %>%gf_bar(~text_ind) %>%gf_labs(x ="texted?",title ="High-Schoolers who texted every day",subtitle ="While driving with no helmet on!!" )
mosaic::binom.test(~text_ind, data = no_helmet_text, success ="yes") %>% broom::tidy()