Inference for Comparing Two Paired Means/ Comparing Multiple Means with ANOVA
Author
Sara S
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(mosaic)
Registered S3 method overwritten by 'mosaic':
method from
fortify.SpatialPolygonsDataFrame ggplot2
The 'mosaic' package masks several functions from core packages in order to add
additional features. The original behavior of these functions should not be affected by this.
Attaching package: 'mosaic'
The following object is masked from 'package:Matrix':
mean
The following objects are masked from 'package:dplyr':
count, do, tally
The following object is masked from 'package:purrr':
cross
The following object is masked from 'package:ggplot2':
stat
The following objects are masked from 'package:stats':
binom.test, cor, cor.test, cov, fivenum, IQR, median, prop.test,
quantile, sd, t.test, var
The following objects are masked from 'package:base':
max, mean, min, prod, range, sample, sum
library(broom) # Tidy Test datalibrary(resampledata3) # Datasets from Chihara and Hesterberg's book
Attaching package: 'resampledata3'
The following object is masked from 'package:datasets':
Titanic
library(gt) # for tableslibrary(infer) # Statistical Inference, Permutation/Bootstrap
Attaching package: 'infer'
The following objects are masked from 'package:mosaic':
prop_test, t_test
Rows: 60 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): Frogspawn sample id, Temperature13, Temperature18, Temperature25
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
frogs_orig
# A tibble: 60 × 4
`Frogspawn sample id` Temperature13 Temperature18 Temperature25
<dbl> <dbl> <dbl> <dbl>
1 1 24 NA NA
2 2 NA 21 NA
3 3 NA NA 18
4 4 26 NA NA
5 5 NA 22 NA
6 6 NA NA 14
7 7 27 NA NA
8 8 NA 22 NA
9 9 NA NA 15
10 10 27 NA NA
# ℹ 50 more rows
Clean the Data
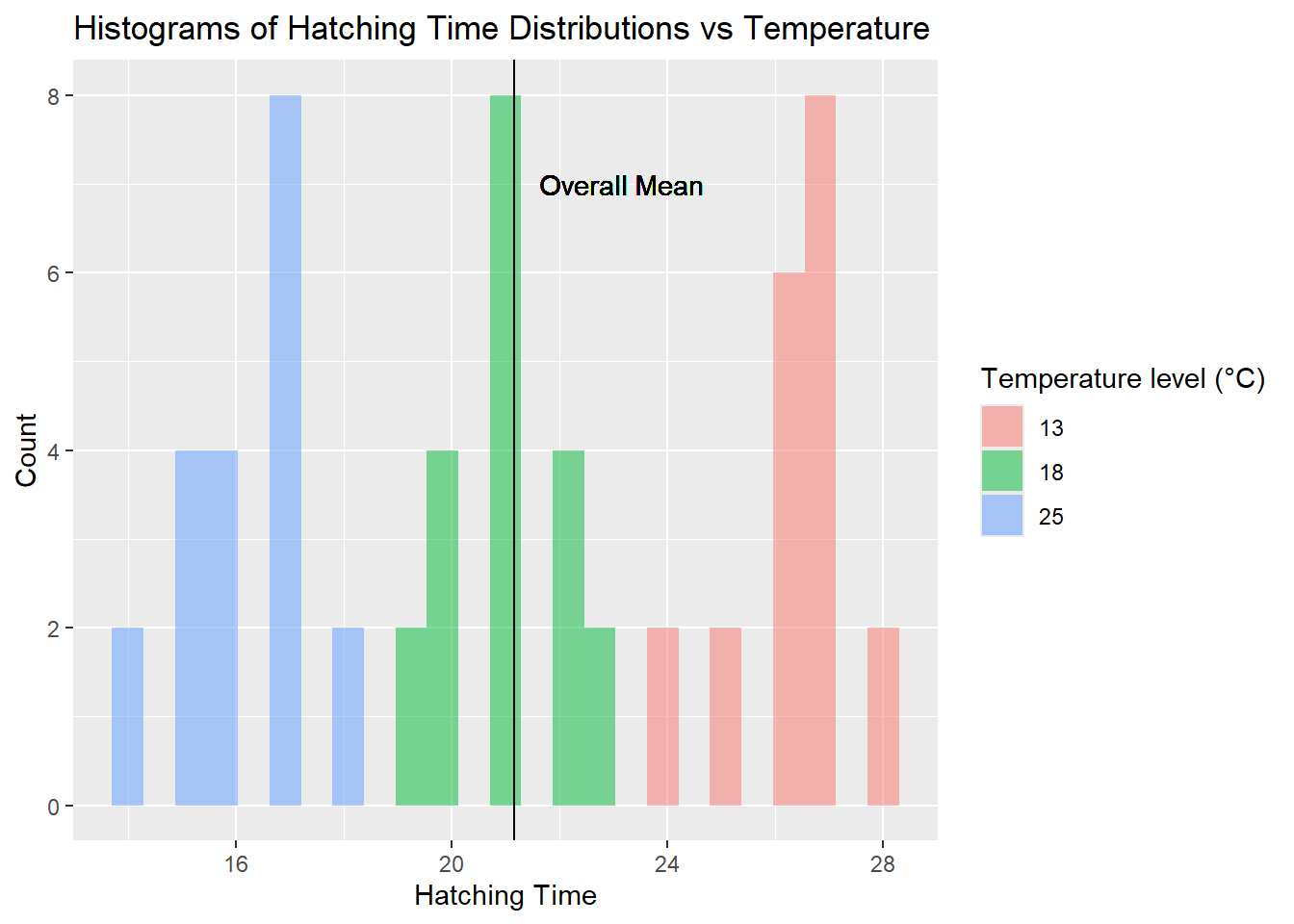
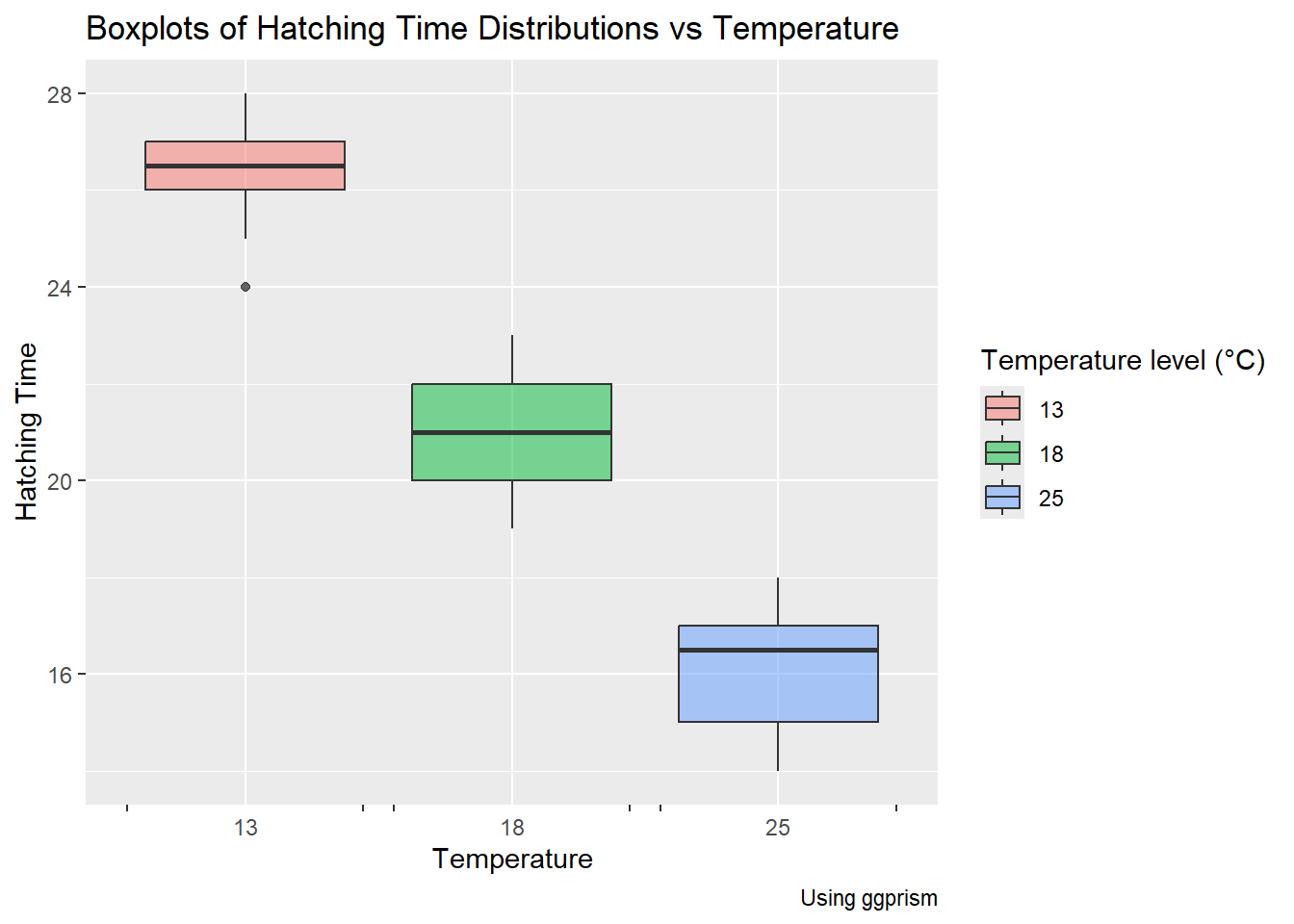
frogs_orig %>%pivot_longer( .,cols =starts_with("Temperature"),cols_vary ="fastest",# new in pivot_longernames_to ="Temp",values_to ="Time" ) %>%drop_na() %>%##separate_wider_regex(cols = Temp,# knock off the unnecessary "Temperature" word# Just keep the digits thereafterpatterns =c("Temperature", TempFac ="\\d+"),cols_remove =TRUE ) %>%# Convert Temp into TempFac, a 3-level factormutate(TempFac =factor(x = TempFac,levels =c(13, 18, 25),labels =c("13", "18", "25") )) %>%rename("Id"=`Frogspawn sample id`) -> frogs_longfrogs_long
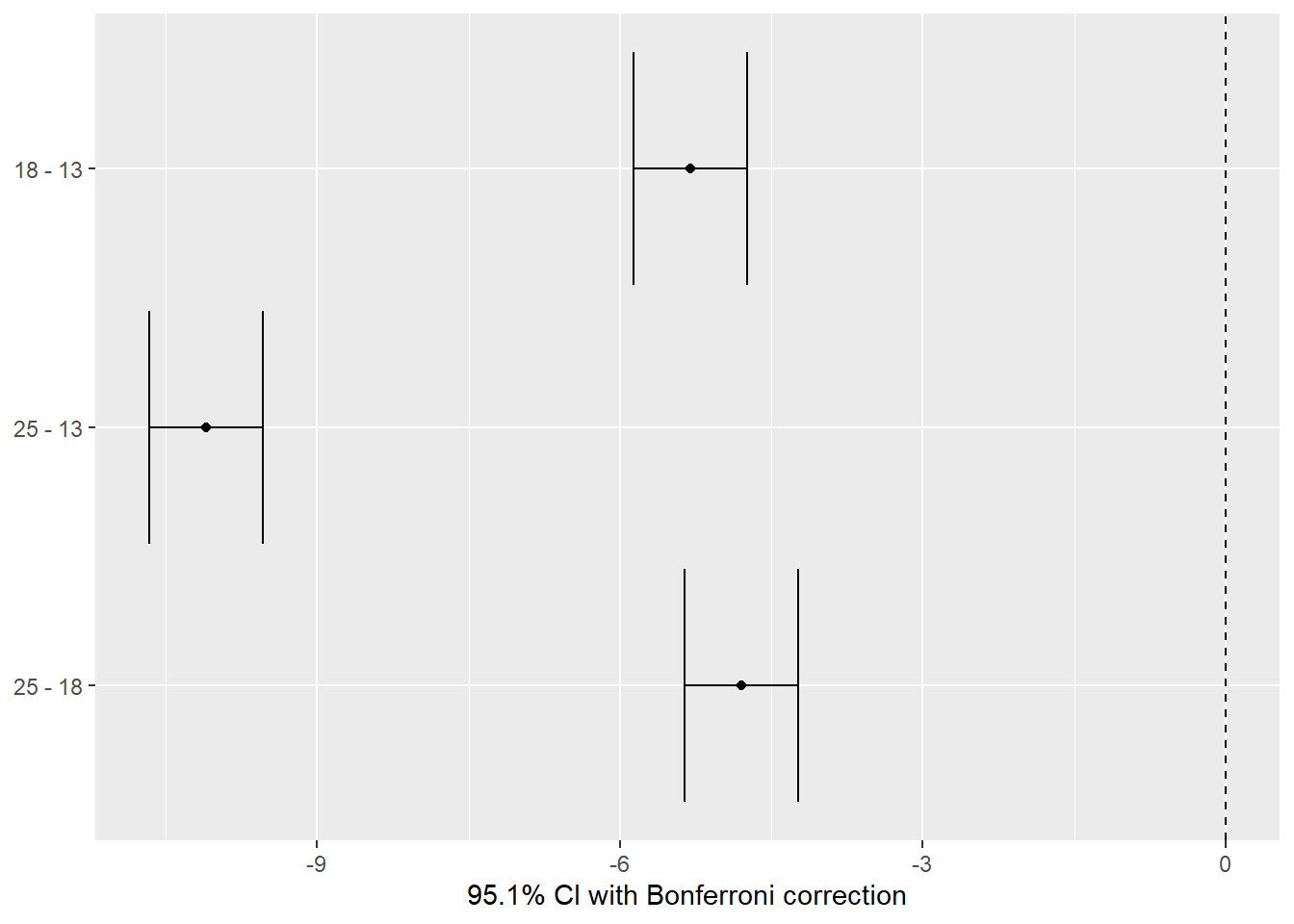
the black points are the difference in the means of the hatching time. yaxis the groups pairwise xaxis difference in means of the groups the lines are the confidence intervals pairwise
variants is square of all the numbers
total sum of squares sst monster number individual number