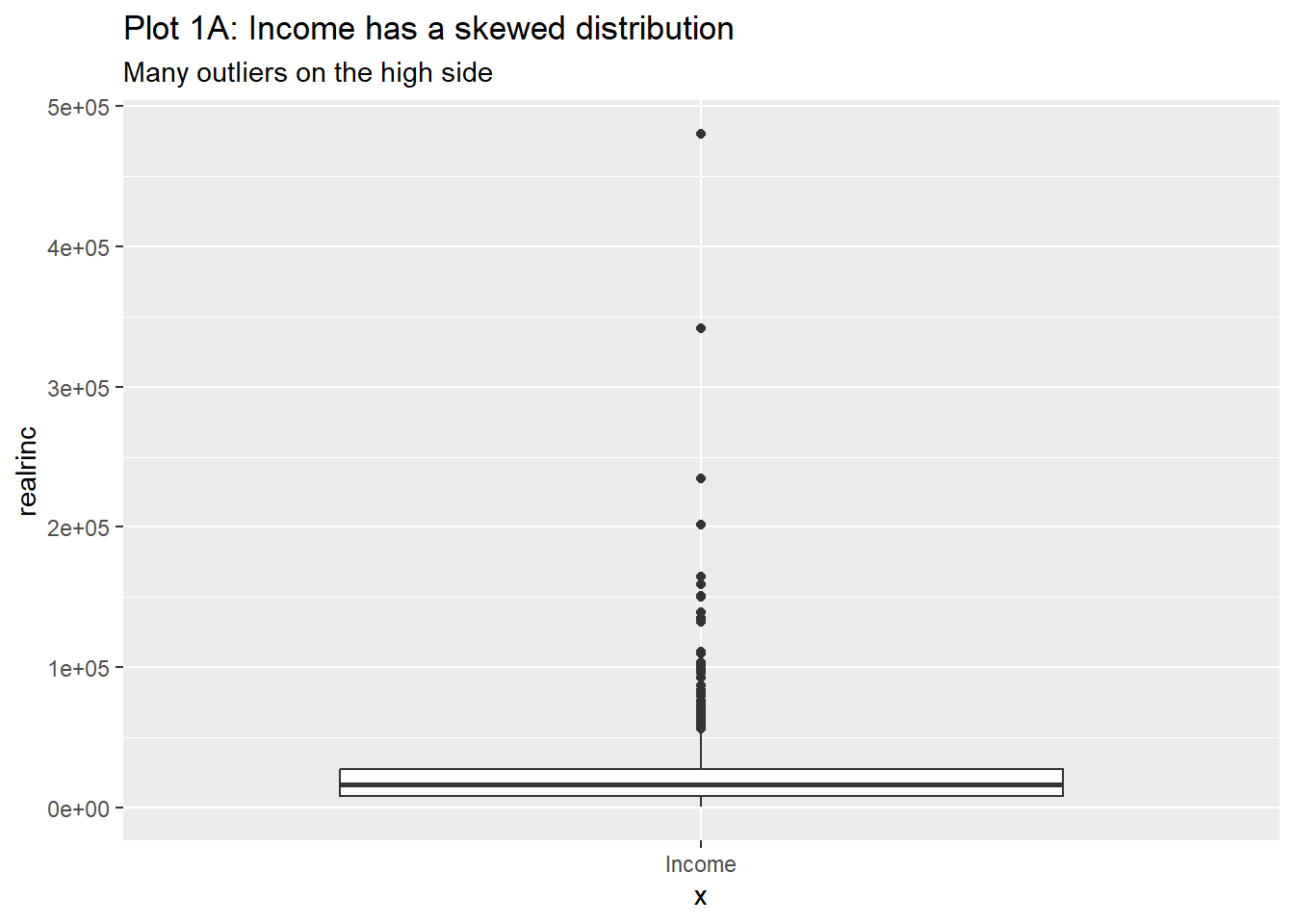
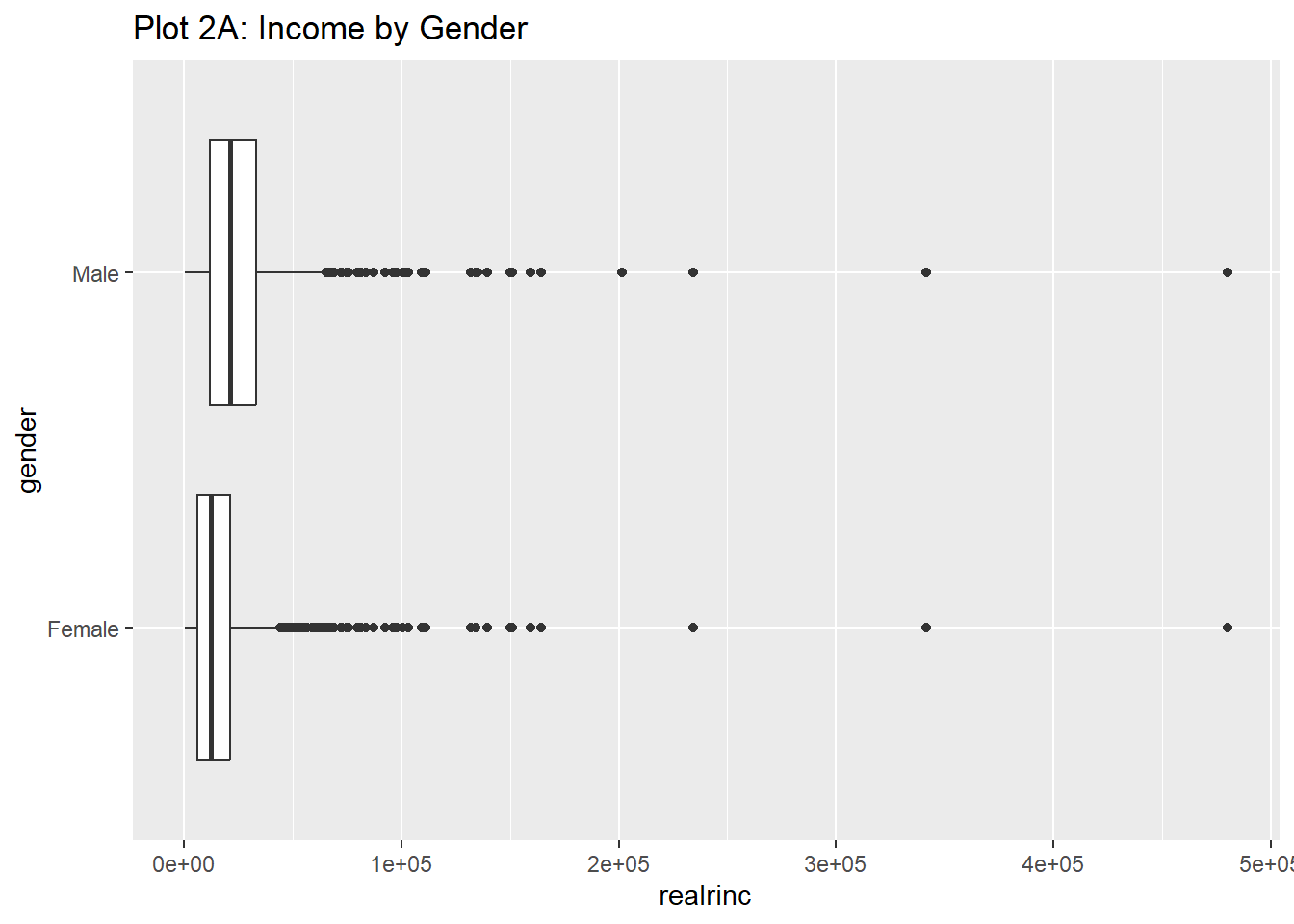
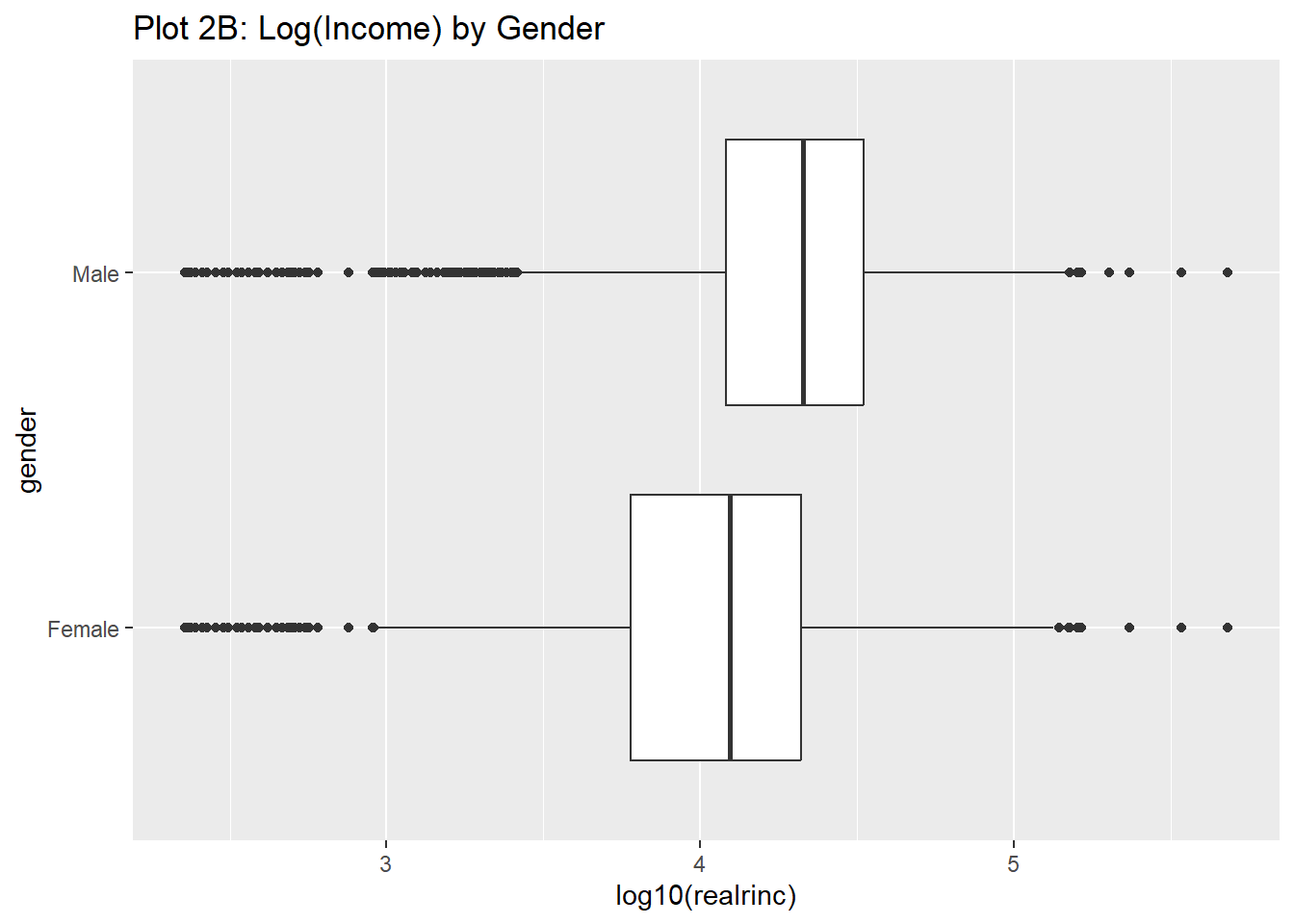
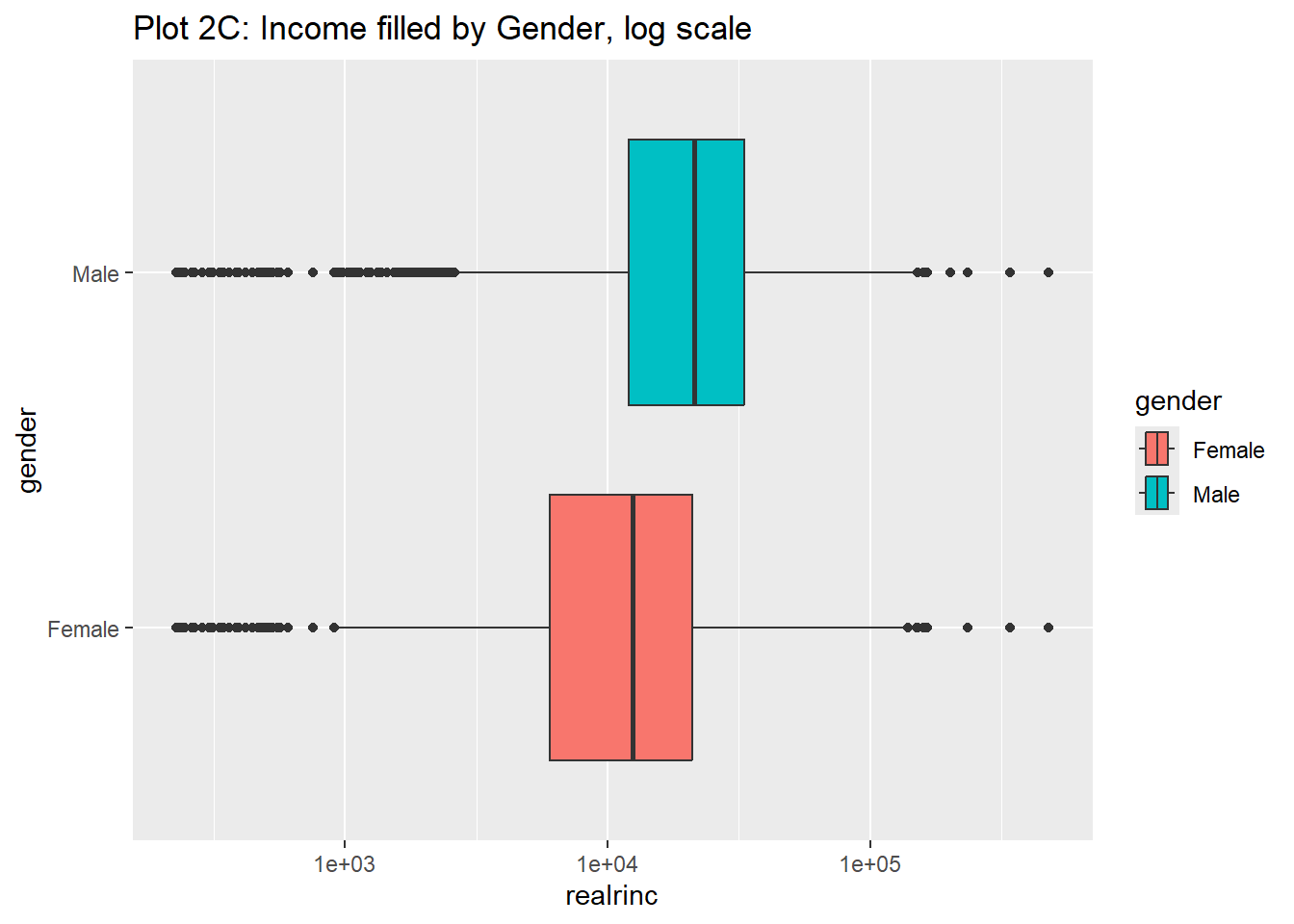
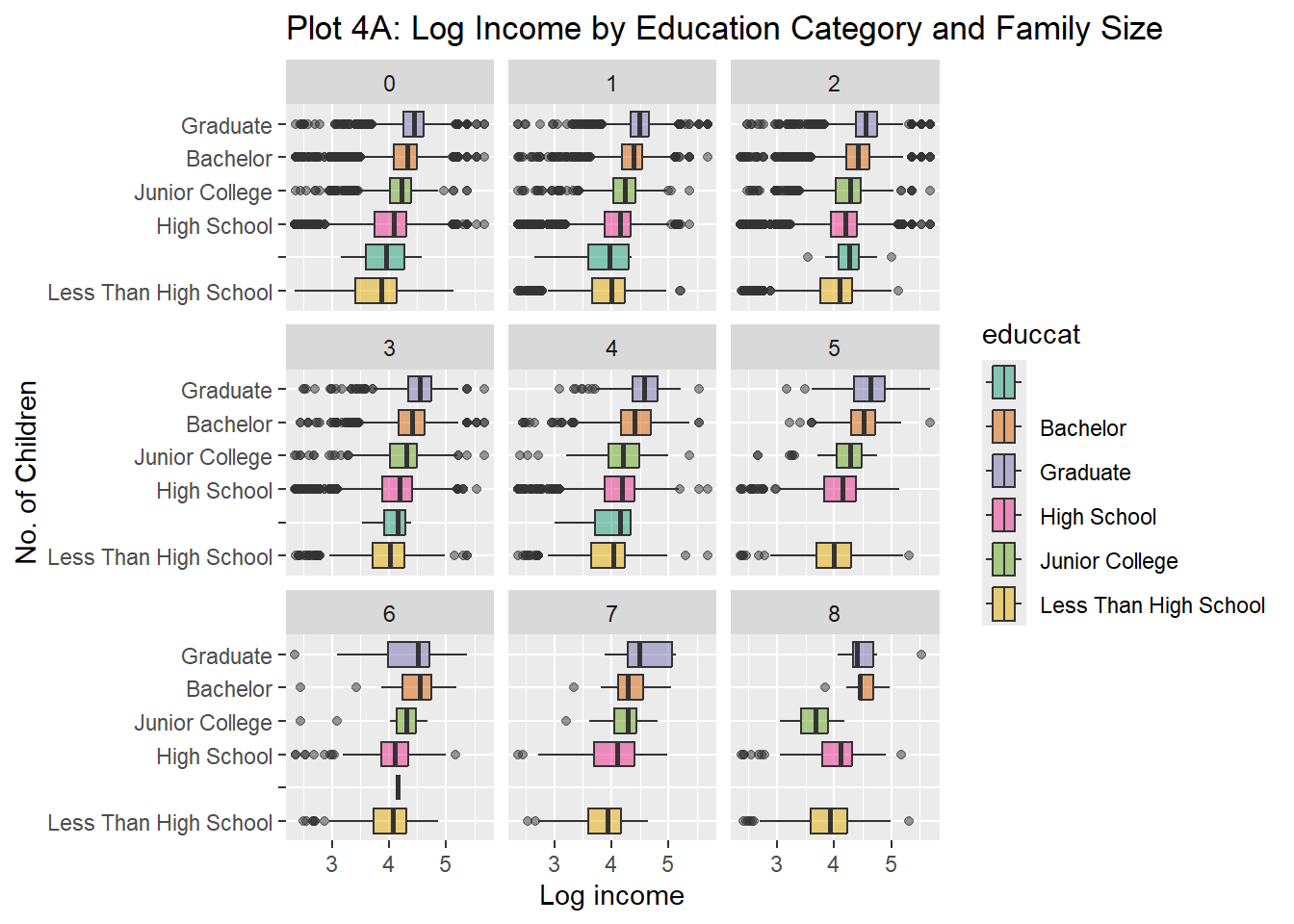
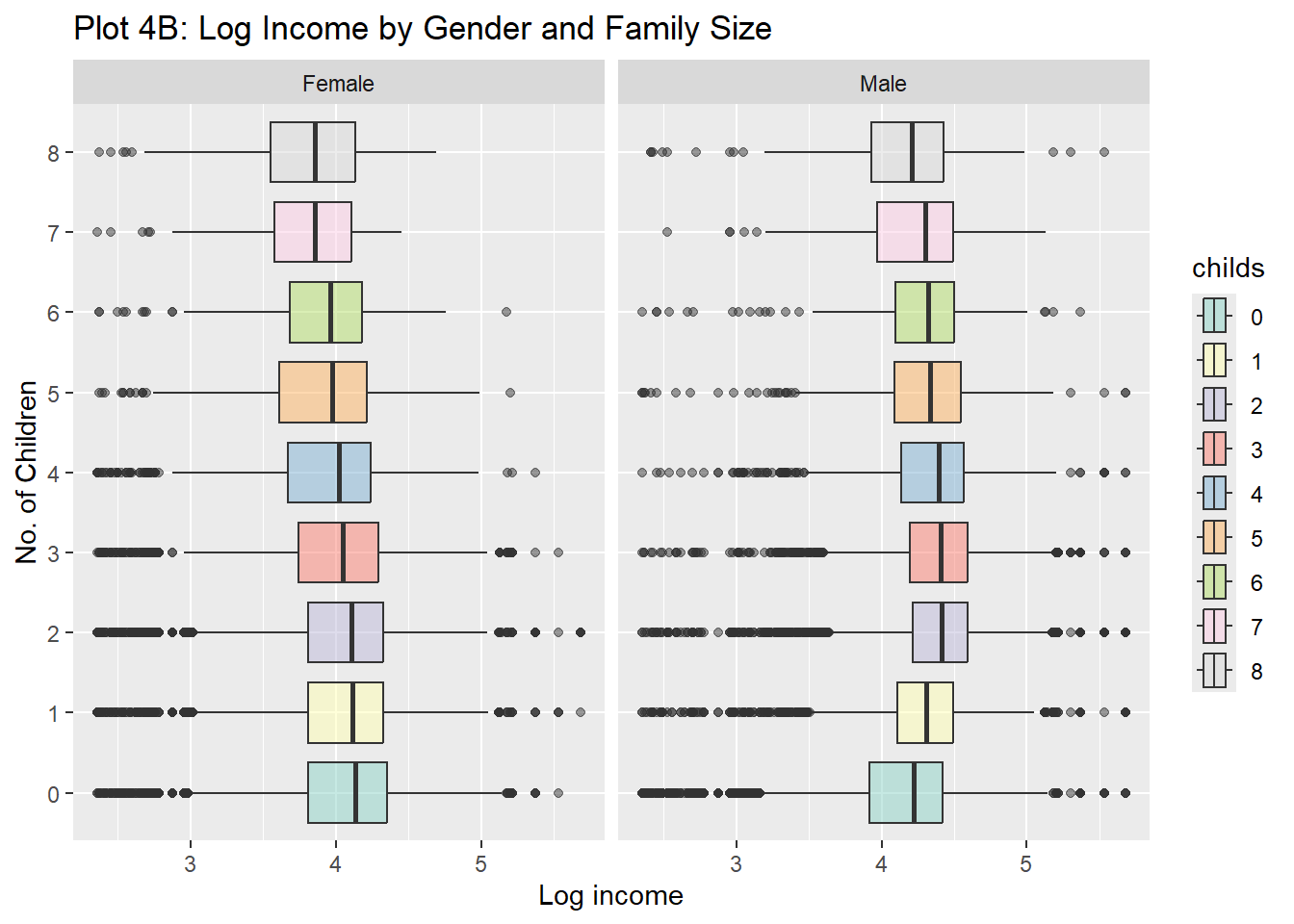
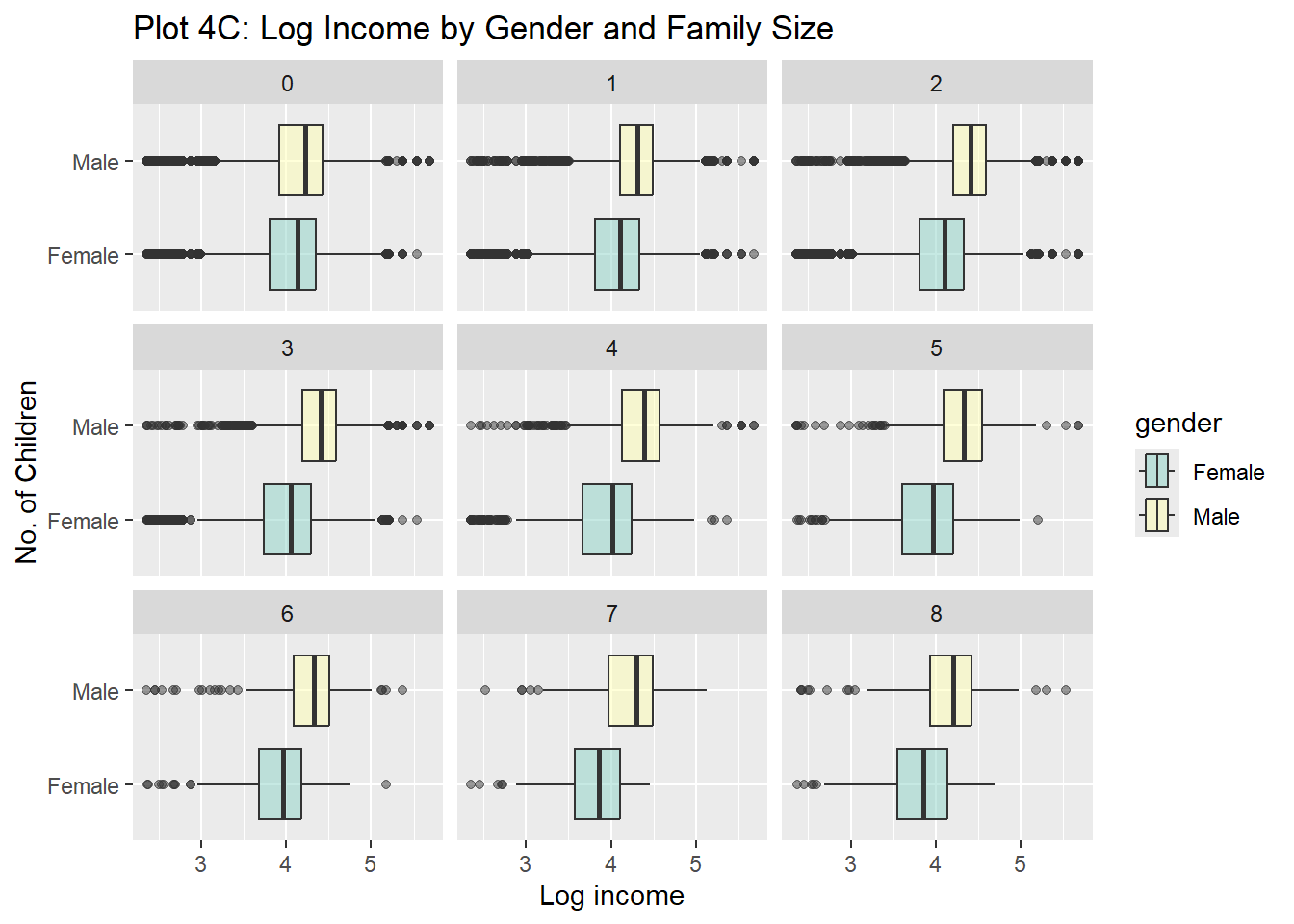
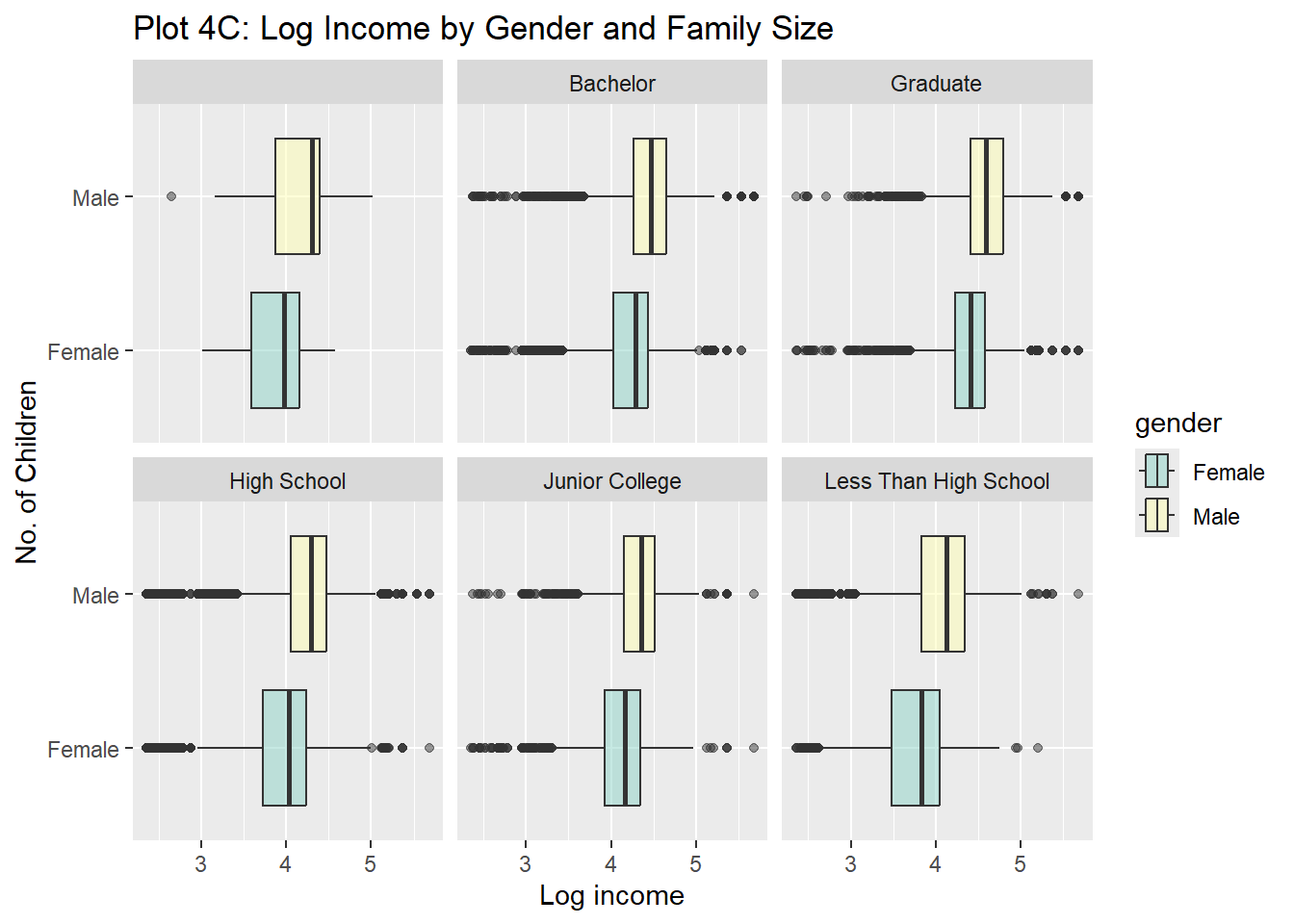
Rows: 61,697
Columns: 12
$ rownames <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, …
$ year <int> 1974, 1974, 1974, 1974, 1974, 1974, 1974, 1974, 1974, 1974,…
$ realrinc <dbl> 4935, 43178, NA, NA, 18505, 22206, 55515, NA, NA, 4935, NA,…
$ age <int> 21, 41, 83, 69, 58, 30, 48, 67, 51, 54, 89, 71, 27, 30, 22,…
$ occ10 <int> 5620, 2040, NA, NA, 5820, 910, 230, 6355, 4720, 3940, 4810,…
$ occrecode <chr> "Office and Administrative Support", "Professional", "", ""…
$ prestg10 <int> 25, 66, NA, NA, 37, 45, 59, 49, 28, 38, 47, 45, 50, 29, 33,…
$ childs <int> 0, 3, 2, 2, 0, 0, 2, 1, 2, 2, 3, 1, 4, 3, 0, 1, 2, 3, 4, 8,…
$ wrkstat <chr> "School", "Full-Time", "Housekeeper", "Housekeeper", "Full-…
$ gender <chr> "Male", "Male", "Female", "Female", "Female", "Male", "Male…
$ educcat <chr> "High School", "Bachelor", "Less Than High School", "Less T…
$ maritalcat <chr> "Married", "Married", "Widowed", "Widowed", "Never Married"…